
1月29日上午,平头哥官网悄然上线一款名为“真武810E”的高端AI芯片,此前被央视《新闻联播》曝光的阿里自研芯片PPU正式亮相。这是通义实验室、阿里云和平头哥组成的阿里巴巴AI黄金三角“通云哥”首次浮出水面。
作为一名IT从业者,我看到这条消息的第一反应是:阿里这次是终于把自己底牌全亮出来了。
以前,大家聊阿里云的时候,可能只是把它当成一个"卖算力"的,尤其是云市场格局稳定后,大家越来越忽略了阿里的技术能力。
直到最近一两年,随着AI大模型的崛起,大家才意识到阿里的技术有多强。阿里千问大模型家族是全球第一开源模型,加上这次真武810E芯片一上线,这三块拼图合在一起,形成了阿里AI黄金三角“通云哥”,阿里也成了全球唯二的"全栈AI闭环"厂商(另一个是谷歌)。
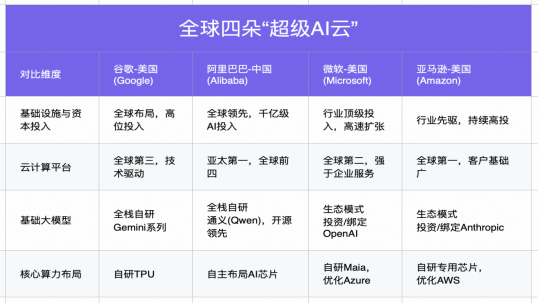
目前,只有阿里和谷歌,是同时在顶级大模型(Qwen/Gemini)、顶级云平台(阿里云/GCP)、自研AI芯片(真武/TPU)这三个最硬核的领域都做到第一梯队的公司。这个含金量,你细品,细品。
下面我回来,我们先看看今天的发布主角真武810E到底是个什么水平?
先看这颗芯片本身的参数:96GB HBM2e显存,700GB/s片间互联带宽,PCIe 5.0×16接口,400W功耗。
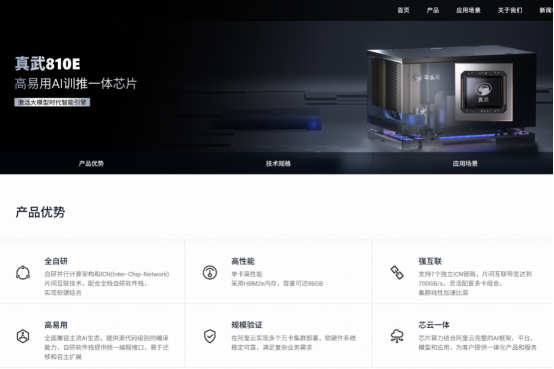
鉴于有些朋友可能对参数不太了解,我呢稍微解释下。
96GB HBM2e是什么概念?它是一种非常高端的显存配置,能有效支撑百亿参数大模型的推理;而700GB/s的互联带宽意味着万卡集群跑起来,卡与卡之间的通信瓶颈小了很多。说白了,这就是冲着大规模分布式训练去的,不是做个边缘推理芯片凑数。
更关键的是,这不是一颗"PPT"芯片。它已经实打实地部署在阿里云的万卡集群里,在跑千问大模型的训练和推理。我问了一个内部的哥们,说真武810E的性能甚至在部分指标上超过了国外主流GPU。已经服务了400多家客户,包括国家电网、中科院、小鹏汽车这种对算力稳定性要求极高的硬核客户,说明已经过了"实验室玩具"的阶段,是真能扛生产环境的。
真武810E的发布也让阿里"通云哥"形成更好的化学反应,达到1+1+1>3的效果。
可能很多人会说,"阿里有的云、模型和芯片,别家也有啊"。但问题是,能垂直整合成阿里这样的,并不多。
微软有云(Azure)、有投资OpenAI,但芯片用的还是英伟达;亚马逊有AWS、有Trainium芯片,但模型层面没有顶级自研大模型;Meta有Llama,但云基础设施完全是别人的。只有谷歌和阿里,是从晶体管到模型权重全自己撸的。
这种全栈自研的好处,说技术点叫"软硬件协同优化",说人话就是:芯片知道模型需要什么,模型知道芯片能干什么,云知道怎么调度最有效率。真正达到1+1+1>3的效果。
举个具体例子:千问3用的是MoE(混合专家)架构,这种架构对芯片的显存带宽和稀疏计算能力要求很特殊。真武810E在架构设计阶段就针对MoE做了大量优化,配合阿里云自研的CIPU 2.0和HPN 8.0网络(那个6.4Tbps带宽的变态网络),能让万卡集群的线性加速比超过96%。
这种优化是买英伟达卡+开源模型+公有云组装不出来的。就像苹果为什么自己的芯片配自己的系统特别丝滑,通用的Android机就是差点意思,一个道理,只是AI基础设施的这个"丝滑",直接 translates to 训练成本降低30%、推理延迟降低70%,这些真金白银的指标。
另外,这里我还得提一嘴千问(Qwen)大模型。很多人以为"通云哥"只是硬件强,其实模型层的强才是阿里敢这么玩的底气。
通义实验室是目前中国AI人才最密集、AI产出最丰厚的AI Lab。千问大模型家族为全球第一开源模型,衍生模型数量突破20万,下载量超过10亿。Hugging Face上榜单一度前十里7个是千问系的。而且之前连Meta那个"牛油果"(Avocado)项目都在蒸馏千问,英伟达CEO黄仁勋在GTC大会上展示的开源模型市场份额图,Qwen更是占了半壁江山。
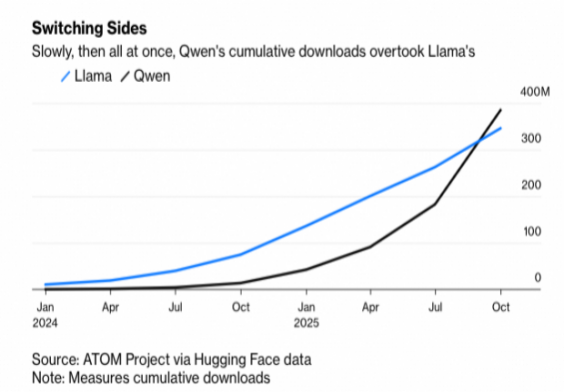
当全球开发者都在基于Qwen开发应用时,阿里自己的芯片针对Qwen做专门优化,就会形成"用我的芯片跑我的模型最快"的飞轮效应。这就像Intel当年的"Intel Inside",只是这次换成了"Qwen Inside + 真武 Inside"。
如今,已经很明显了:阿里不只想做中国的英伟达或者中国的OpenAI,它想做的是AI时代的"水电煤"基础设施。
阿里这次芯片的发布价值不是某一颗芯片或者某一个模型的单点突破,而是中国终于有了一家能在AI全栈技术上跟国外最顶尖科技公司正面刚的"科技航母"。这不是简单的商业竞争,这是在定义下一代AI基础设施的游戏规则。
给阿里这次点赞!