

11月20日,由全球化媒体智库——霞光社ShineGlobal&霞光智库联合阿里云举办的AI火花π「模型应用·编码新未来|WAVE2025泛互联网全球大会」在上海成功举办。
活动当天,阿里云智能集团通义实验室新生态及中小企业模型合作负责人苏吉普,带来主题演讲《通义大模型最新技术进展及产品化探索》。
以下是分享内容,霞光社编辑整理。

大家好!感谢主办方的邀请。我们知道,AI成为一个全民热点话题已经好久了,以大模型为代表的生成式人工智能技术、应用,在过去几年发展速度特别快。从搞端侧大模型上车、进手机,到负责阿里云规模庞大的创新生态及中小企业模型合作,这两年我最大的感受就是:每天起床都想“佛系”一下,结果一睁眼就被需求追着跑!每天都想从从容容,游刃有余的,但实际是是每天都忙忙碌碌的,节奏非常紧迫,从去年30min线上聊好一个客户的卡点问题及整体合作,到今天已经压缩到15min聊好一个客户。
这个现象主要是因为单客户的需求越来越多,找我们合作的客户也越来越多,真的是千行百业,特别是中小企业。
我们在云栖大会讲过,自2023年4月通义千问大模型正式发布后,初期中小企业在大模型上的支出处于“低水位”,但2024年开年后,增长曲率明显变化,2025年增速进一步陡峭。2025年8月较2024年1月,百炼平台上中小企业的大模型支出翻了约200倍。200倍的增长有行业趋势,背后也写满了我和同事们的努力,写满了这两年的酸甜苦辣与奔波,感谢能有个机会让我参与其中。这次技术平权和流量场变化是利好中小微企业的。
2022年11月30日,ChatGPT3.5问世,到现在为止满打满算接近三年。2023年的春天,国产大模型刚开始是一码难求,大家知道那个时候体验国产大模型要有邀请码,当年夏天陆陆续续有些大模型备案通过,并可以通过API的方式接入,后面到了所谓的百模大战,然后去年大家认定是智能体元年,真可谓眼花缭乱,那么2025年有哪些关键发展事件,我还没来得及总结,今天这个场子,我讲讲我的一些个人的非全面视角观察,如有讲的不对,请大家指正。

第一个点我想提下模型效率革命。今年年初,DeepSeek的爆火让大家感受到了模型效率革命。模型很便宜,使用的卡资源很低,但依然做到顶尖模型的水平,并且从应用发展角度也再一次做了全民二次普及;Qwen模型和DeepSeek在春天持续引领开源模型行业,这个原来Llama开启的阵地上我们有Flag、也有规模衍生。这里面我想强调一点,模型APP用户量固然重要,但这个模型精度还在快速迭代提升的时期,基模能力更加重要,我已经在很多场合表达了这个观点,当然网搜技术也很重要,这里不再衍生。
第二个点我想讲讲国产模型出海契机。今年4月份,OpenAI 4.5发布之后,给很多国产模型出海带来了机会——同样的效能精度,国外百万token要花好几个、几十个美金,而我们一块人民币可以拿到百万级token,我们也在4月底发布了Qwen3系列,很多国外企业就反过来调了国内站点的模型,我们看到了国产模型出海的场景。今年,我也看到包括阿里在内的AI企业在新加坡、香港都陆陆续续开了站点。模型出海这是大势所趋,对我们及全球用户都是利好。
第三个点我想提下非文本模态生成类模型的能力跃升。今年7、8、9月随着WAIC以及云栖大会的一个个开幕,我们看到了国内外图片和视频的生成领域的模型进展,可以说生图、生视频的模型效果也到了2022年的ChatGPT时刻。我们发现大家不再只是生成一些搞笑娱乐的图片、视频,在产业生产级的需求面前,模型生成效果似乎开始更接近我们的指令要求。但不可否认的是,在多模态生成模型这条路线上,我们还有很多路要走,多模态模型比语言模型在训练和推理上要考虑更多的问题,需要处理大量的元信息,更需要适应GPU的内存,还要考虑推理生成的时长与内容一致性、风格控制和内容的多样性等。这些因素都增加了视频模型开发和使用的复杂性,但我相信接下来的半年多国内外会有更大幅度的模型能力提升,甚至是惊喜。
最后,我想提一提世界模型。语言模型是对互联网为代表的世界信息化知识的表征理解及生成,世界模型的定义特别多,我的理解是AI对真实世界的内部模拟器,它要讲把视觉、语言、动作、因果推理统一起来,让AI不仅能“看图说话”,还能“理解发生了什么、接下来会发生什么”。
我们知道,传统大模型(比如ChatGPT)擅长“回答问题”,但它没有对世界的连续理解。啥意思,我举个例子,你问它“杯子掉地上会怎样?”,它能答“会碎”,但无法模拟“杯子下落→撞击→碎片飞溅”的全过程。而世界模型的目标,就是让AI:感知环境(看视频、读传感器数据);构建内部表征(理解物体、空间、因果关系);模拟未来状态(如果我推这个盒子,它会往哪滚?);据此做决策或生成内容(比如生成一段符合物理规律的视频)。
世界模型≠一个具体产品,而是一种新范式,是让AI从“被动应答者”变成“主动理解者+模拟者”,世界模型的最终目标是要让模型像人一样,在脑中构建一个可推理、可预测的“虚拟世界”。
这也是为什么很多人说:世界模型,可能是通往通用人工智能(AGI)的关键一步。所以我想通过这个例子表达,全模态是未来,世界模型是未来,是我们真正应该去追求的。这里说远了,回过来说说整个行业温度。国庆前后,随着Wan2.5预览版、Sora2的发布,以及李飞飞教授新的世界模型的发布,还有可能马上要发的谷歌新一代Nano Banana,我观察到最近一两个月很多热点讨论都是围绕世界模型开展的,大家都在讲物理规律方程派、生成概率派、融合派哪一个是未来,不管最终哪一派登顶,世界模型的路还很艰巨,期待明年有世界模型对应的“ChatGPT时刻”到来。
总体而言,在模型厂商的领域,即将过去的2025年国内模型基本格局开始凸显,确实是云厂商和垂直模型厂商为主的格局,这里面以阿里云为代表的云厂商具有很大的模型训练优势和推理供给能力。

我们接下来讲讲千行百业和大模型的结合这个话题。
大模型的技术毫无疑问解放了我们商业的想象力,使得很多行业的产品交互、企业赚钱的方式方法都有一些变化。
我负责支持阿里云全国中小企业、创新企业、生态企业的模型合作业务,我不太喜欢一直坐在办公室,过去两年我基本保证每周至少有三天在外面见客户,听企业讲用大模型技术在做什么样的功能、什么样的产品,以及怎么把它卖出去,怎么赚钱,给他们出主意找解法、弄清楚卡点问题、梳理产品技术业务架构、推荐合适的模型。
我看了很多企业,走了很多地方,讲实话很累,我需要实地去解决一个个前线业务同学求助和客户的大模型接入问题,小到一个扩TPM计算、badcase请求分析,大到整个Agent及业务流梳理,商业模式及产品共创,有微观也有宏观。一个个客户、一个个行业、一些新的产业链重组、国内外数字游民大模型应用创业,但我看到了国内外大模型行业应用的浪潮。给我感受大模型影响深刻的有三个典型方向:智能终端、泛互联网、产业SOP。我分别讲三个案例。
首先说智能终端,玩具、眼镜、键鼠、教育硬件、耳机录音笔等等这些消费电子拥抱大模型的速度很快,这里我挑一个讲讲。我们有个客户,以前做电视遥控器的,传统的电视机遥控器,大家知道搜索效率,比如你搜《还珠格格》,差不多要十几秒、二十几秒才能把这个名称输进去,然后它给你推荐让你选择确定,大概还得几秒。可是只要加一个识音的按钮,就能通过语音的方式说我要看《还珠格格》或者我要看小燕子和五阿哥,就能秒出结果。确实大模型给用户带来很好的体验升级,方言都支持,语义理解即可,不需要关键匹配,技术带来的泛化性很符合老年人和小朋友。
今年6月我们在北京坊做了一场AI火花市集活动。有一个客户做了一个闺蜜机,我现场户外测试了一下,我说我想看两个人在船头吹风的电影,他就跳到《泰坦尼克号》两个人在船头吹风那一节开始播放了。这是怎么做到的呢?我们有一个视觉理解模型,客户把很多影片让这个视觉理解模型全部看了一遍,具体来来说就是对抽帧的画面做了做了理解解析,包括里面的人物、字幕、元素和时间轴都做了落库结构化,反过来可以通过语音的方式去搜索,免去了片名→剧集→进度条的反复试来试去。
其实在消费电子领域,大模型更多是做用户体验的升级,当然也有类似于去年火的Rabbit R1、AI Pin这种新的产品,这块我相信我们有很大的产业优势的,我也经常去深圳出差,就是这个原因。
我接着讲一个泛互联网的场景,这里我们不讲伴聊、游戏、娱乐、功能等强2C的互联网APP,这块大家应该看的听的应该非常多了,我们讲讲互联网的VOC(客户之声)。我们知道,其实用研和产研这些行业已经在用大模型了,它对于处理海量用户的评论数据非常有帮助,原来请一个咨询公司要十几天才出一个报告,今天通用大模型瞬间就处理完所有抓出来用户评论数据,当然客户自己要去合规爬取的数据,模型只是做数据处理,做打标、摘要、提取、聚类、深入分析等。比如,我是化妆品品牌公司,就可以快速知道我的化妆品昨天在全网的舆情及用户真实评论是怎么样的。包括我有一个做高端地产的客户,他们把所有销售门店或者电话销售的话术全部收集回来,要看销售人员有没有给客户讲清楚房子、小区情况,这也是非常好的理解用户心声的机会,能做话术质检的分析及生成改善建议。
最后我再讲下产业SOP,具体来说是企业内部提效的案例。流通行业在上海非常发达,其实对大模型的需求非常旺盛。比如说化妆品、箱包、食品、饮料等快消行业,这类代理贸易型的企业可能是一千个销售配五个法务,旺季的时候在合同件审核上是非常难受的,因为是乙方嘛,要把货卖出去,去了甲方之后,甲方很强势,一定要用甲方的合同模板,一定要用甲方的收据,拿回来都是非标的,法务就炸了,我就5个人怎么对你1000个人?所以我们去年推了一个通义法睿,支持把自己企业的审核规则加进去,反响非常好,当然我们也更多是提供API给到更多具有行业认知经验的工具厂商做成更好的SaaS供给给大家。

在我从淘宝新制造进入阿里云的时候,阿里云的IaaS、PassS已经发地非常成熟和强大了,已经是亚太第一云了。那么在大模型时代,公司也在努力建一个更好的MaaS平台——模型调用平台,也就是我们的百炼平台。做MaaS,除了调用要有一个好的模型在里面放着。
那么先报告一下我们的模型,过去以来,我们给大家的印象应该就是开源,目前我们开了三百多个模型。其实,在过去的几个月,我们在大模型上持续演进,推出包括超万亿参数的Qwen3-Max,顶级编程能力的Qwen3-Coder,视觉理解模型Qwen3-VL,全模态模型Qwen3-Omni以及下一代模型架构Qwen3-Next等大语言模型;视觉基础模型通义万相更新至Wan2.5,涵盖文生视频、图生视频、文生图和图像编辑四大模型;语音模型家族通义百聆全新发布,涵盖语音识别和语音生成两大系列。截至目前,通义大模型衍生模型数量已突破18万,在全球下载量超7亿,成为全球第一AI开源模型。
这两天千问的APP出来,登上了热搜。我想报告一下,在这个2C的产品上,我们是把最强的模型给大家免费使用的,大家尽情地去薅羊毛,Max模型的好处不多说了,我们很多2B客户说能不能把Max模型降个价?因为Max模型和Plus模型的价格差了10倍+,所以我们目前是拿最好的模型给大家免费使用的。
你可能会说,我API接入还要考虑成本、速度。没错,我想告诉大家,我们也有对应版本的模型给大家使用,Plus模型是性价比均衡模型,Flash模型成本低、速度比较快。大家看到很多场景可以用Flash满足,这个模型非常便宜,在单次128K输入的场景下应该是0.15元/百万token。

除了语言模型、编程模型之外,我们也研发下一代架Qwen3-Next。我们认为Context Length Scaling和Total Parameter Scaling是未来大模型发展的两大趋势,为了进一步提升模型在长上下文和大规模总参数下的训练和推理效率,我们设计了全新的Qwen3-Next的模型结构。该结构相比Qwen3的MoE模型结构,进行了一些核心改进。例如混合注意力机制、高稀疏度MoE结构、一系列训练稳定友好的优化,以及提升推理效率的多token预测机制。那么基于Qwen3-Next的模型结构,我们训练了Qwen3-Next-80B-A3B-Base模型,该模型拥有800亿参数仅激活30亿参数。这个Base模型我们实现了与Qwen3-32B dense模型相近甚至略好的性能,而它的训练成本,GPU hours仅为Qwen3-32B的十分之一不到,在32k以上的上下文下的推理吞吐则是Qwen3-32B的十倍以上,实现了极致的训练和推理性价比。
当然,我们也基于Qwen3-Next-80B-A3B-Base模型,同步开发并发布了Qwen3-Next-80B-A3B-Instruct与Qwen3-Next-80B-A3B-Thinking。那么Next的特点在哪里?我们看到“激活比”空前地拉大。
这个比例越大代表什么意义?我是一个模型,我很庞大,我能力也很强,但是我在完成你的具体任务的时候,我只用局部的神经元就完成了。大家是不是觉得讲的太技术了没有体感再我举个例子,比如说下午2点你非常困,你开车经过一个红绿灯口,突然红灯变成绿灯,你下意识迷迷糊糊把车开过去了,可能是跟车,也可能你是头车,然后你开过去后嘟囔了一句,“好神奇,我怎么把车开过去了”。这个时候你知道我们人类的大脑只用了一小部分的神经元参与了这次开车的运算过程。理论上讲,我们推出80B,按照以前的方式大概要动用1/10——也就是80亿左右参数,可是看到现在只有多少,是30亿,所以这个激活比是非常大的,效果也很好。
除此之外,还有一些图片的模型,比如Image模型。这个能解决什么问题?这个模型很好解决了中英文渲染问题。去年大家生成一张图片,里面如果带有文字基本上会出现乱码,火星文或日文的感觉,那么Qwen-image这个模型很好地解决了这个问题。并且我们还搞了一个编辑模型,Qwen-Image-Edit,哪里不对改哪里,非常棒。我经常用edit,我看几个例子。我们先看在右上角的两张字母表图。我们看到左边的N是橙色的,右边的N是蓝色的。以前我要把橙色变成N,其他的字母不要动,确实变了,但是其他的会动掉,这叫指令不遵循。而edit就是严格遵循了,这就是指哪打哪。包括下面餐盘上的头发次去掉后背景菜单并没有更乱掉体。
当然,我们也持续迭代VL视觉理解模型,Qwen3-VL是全新的多模态视觉-语言模型系列,在前代模型基础上,Qwen3-VL在视觉理解能力上实现了显著提升,同时保持了强大的纯文本处理能力。VL要看懂世界、理解事件、做出行动,已经有很多人用过这个模型了,我们很多IPC的客户也在用这些模型。
我们讲了语言模型、视觉理解模型、生成模型,我们希望做一个全模态模型,这个模型像人一样能听、能看,千问推出了Omni模型,Qwen-Omni模型能够接收文本、图片、音频、视频等多种模态的组合输入,并生成文本或语音形式的回复,提供多种拟人音色,支持多语言和方言的语音输出,可应用于文本创作、视觉识别、语音助手等场景。我们看一个Omini的一个应用视频,这个视频我们看到同时输入了语音流、视频流,这就是多模态输入,当然我们看到很多客户也把Omini用成语音端到端模型。
我们还有对应的ASR和TTS,Qwen和百聆系列。不知道大家有没有体验过,这两年许多APP里面慢慢把传统ASR换成大模型版本的ASR。一个直观的印象是,昨天晚上我在回上海的高铁上,环境特别嘈杂,我在很微弱的语言说得非常不清晰的情况下,千问也非常清晰地识别到了内容和我的意图。以前,我们用各种各样的语音助手和车里面的语音助手,你会发现说了半天之后,转写的我的语音结果一看就识别错了,更别提准备给出一个正确答案了。
提到语音翻译,我给大家看一个实时翻译模型,这个模型的好处在哪里?我们看下面这个案例。
画面中的人讲了一句This is foundation,what is foundation?
foundation是基础。如果纯粹的语音翻译,就翻译成基础了。可是这个画面里面我们明明看到这个人在化妆台前面,所以这个翻译模型同时把视频流灌进来的时候,不只是听还要看画面,这样翻译的时候会说这是粉底液,什么是粉底液,这个就非常准确了。
我们最后还要讲我们的生图生视频系列模型-Wan。刚刚前面讲到非文本模态的生成已经达到了三年前的ChatGPT时刻。我们目前聚焦在图片生成、视频生成、数字人三个领域上。
通义万相模型家族非常庞大,现在目前最新的是Wan2.5预览版,很快推出Wan2.6。Wan2.5预览版相信很多人都已经知道它最大的特色,是目前全球为数不多能做到端到端音画同步的模型。大家在各种社交媒体上看到的有AIGC生成音频的视频,基本都基于Wan2.5,当然有可能用到了国外的Sora,Veo。我们也看一个有意思的视频。
刚刚小女孩说会被“蜇”,这个“蜇”前面的停顿生成感非常好,在生成视频的领域上对音频的要求非常苛刻,Wan2.5预览版非常好的支持了这点,包括带背景音生成。我们再看一个例子。
你看这个视频就是把制作好的声音文件扔进来,按照声音和Prompt要求生成一个跟声音匹配的画面,生成的也非常好。今年以前的时候,大家做AIGC剧,如果这个人说话嘴唇对不齐,就不播放这个人的画面,换到另外一个人,另外一个人播放的时候他的声音从画外音飘进来,这样你就看不到嘴唇不对齐的问题。但是我们知道在横店影视城真人拍摄里面,不可能说拍出来视频里面这个人讲的时候,播放另外一个人的画面。
Wan2.5预览版也进一步提升了图生视频指令遵循能力,支持复杂变化,画面稳定保持,能够比较轻松还原各类复杂运动,并进一步强化运动的流畅度和可控性,包括各种各样的声学、美学的控制。以及我们在视频生成领域,比较头疼的一个问题是,体操运动员视频生成,往往转的过程中会变成三条腿、四条腿,这个也较好的做了优化修正。
时间关系,我不一一展开其他模型。其实我们还发了一些垂直的模型,比如翻译大模型,可以对文本、图片、文档、网页进行翻译;针对消费电子行业,我们做了对应的解决方案,纯音频、音视频通话的能力都能组合提供;针对生态MCP方面,百炼已经提供了上百的MCP服务,有很多三方优秀的,涵盖了各种各样的生活技能。我认识一个嘉兴的朋友,做高端床的,我和他聊过,他就希望老人在这个陪伴天一天大多数时间的康养床上能够接入大模型音频对话,核心是想接入更多优秀的MCP服务,12306、股票、天气,这个比普通网搜服务要好的多了。
我们讲讲这么多优秀的模型,那么企业侧怎么接入。其实大家使用模型的时候,一般都是直接调基础模型API进行自组合,阿里云百炼支持通过API调用大模型,涵盖OpenAI兼容接口、DashScope SDK等接入方式。此外,我们知道,大模型具备强大的语言能力,但仍有一定的局限性,例如难以处理私有领域问题、获取最新信息、遵循固定流程,以及自动规划复杂项目。为此,我们的百炼平台推出了大模型应用:智能体应用、工作流应用,增加了知识库检索、互联网搜索、工作流设计及智能体协作等功能,显著扩展了大模型的应用范围。
当然,如果你在尝试了一通方式,例如Prompt工程、插件调用等优化方法后,模型表现仍然不及预期时,那么我其实建议你试一试百炼平台上的模型调优。模型调优作为改进模型表现的核心策略,可以很好地提升模型在特定行业/业务的表现,对齐人类偏好,降低输出延迟。模型调优包含模型微调SFT、继续预训练CPT、模型偏好训练DPO三种模型训练方式。
模型在调优过程中,会学习训练数据中的知识、语气、表达习惯、自我认知等业务/场景特征。也由于已经在训练过程中学习到了大量特定行业/场景的样例,训练后模型One-Shot或者Zero-Shot的Prompt效果会比训练前Few-Shot效果更好,这样可以节省大量输入token,从而降低模型输出延迟。
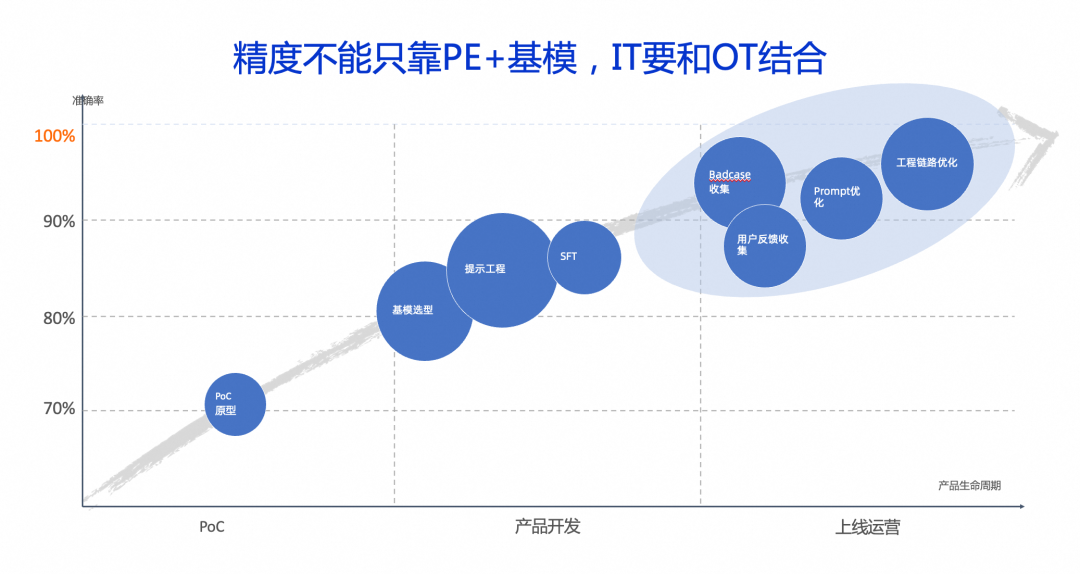
最后,我想想概要讲讲精度与业务效果控制。很多人觉得大模型Agent就是一个Prompt,我就是不断选择最好的模型,改出最好的提示词,注入经验和行业SOP做最好的Agent架构,智能体一上线就万事大吉,我个人的观点,大模型本身也是一个技术,也是属于IT的范畴,一定要和运营OT进行结合,最终效果往往是需要IT和OT两面一起合力,不能单纯只依赖一个优秀的Prompt和选取一个好的模型来处理,还是要多结合很多东西。
以大模型为代表的生成式人工智能不只是技术的跃迁,它也正在重新定义知识如何产生、如何流动、如何被使用,我们从图书馆、互联网搜索引擎、再到直接问大模型应用我们想要的知识,越来越便捷和平权。
今天,我们站在一个全新的起点,当下不是终点,不是泡沫,而是一场深刻变革的序章。
通义愿做这场变革中的一份子,我和我的同事们努力的意义就是让每个开发者、每家企业、每个普通人,都能平等地调用智能、创造价值。因为真正的智能,不属于某一家公司,而属于每一个敢想、敢试、敢行动的人。
谢谢大家!