

在用户「苦AI胡编乱造久矣」的今天,AI大模型该如何摆脱「垃圾进,垃圾出」的魔咒?
文 | 佘宗明
这年头,比冷不丁梆梆就两拳掌门人张八旦更能「一本正经地胡说八道」的,是AI。
去年初,DeepSeek火了后,就有篇文章在网上热传,题目是「DeepSeek的胡编乱造,正在淹没中文互联网」。
爱胡编乱造的,不只是DeepSeek。如果说幻觉是病,那它称得上是大模型的通病。
前不久,香港大学人工智能评估实验室(AIEL)就发布报告称,大模型普遍存在「严守指令但易虚构事实」倾向,事实可靠性仍是全球大模型共同的短板。
更早之前,去年2月,清华大学新媒沈阳团队的报告指出,市场上多个热门大模型在事实性幻觉评测中幻觉率超过19%。
可以说,生成式AI将互联网时代的「信息过载,事实稀缺」情形进行了几何级放大。
那怎么让AI离加冕「事实派」近些,离「满嘴跑火车」远些?
打破大模型「GIGO(即垃圾进Garbage In,垃圾出Garbage Out)」魔咒,至关重要。
究其前提,就是要回归「Clean Data > Big Model(高质量数据优于大模型)」的逻辑基点。
01 /
为什么AI给出的答案总是「听着像真的,其实是编的」?它怎么就这么爱胡编乱造?
去年9月,OpenAI在论文《为什么语言模型会产生幻觉》中对此做出了分析,我的总结是:因为大语言模型(LLM)「本性难移」。
大模型本质上是个「随机鹦鹉」,运行底层逻辑是「下一个词元预测」(Next Token Prediction),这决定了,它是个贝叶斯预测大师,而非事实考证者。
其长处在于,能根据高频统计关联对强规律性知识(如语法规则、编程程式、基础常识)进行快速「复现」。打个比方,你问它「法国首都是哪里」,它会因为「法国首都巴黎」几个字在海量文本中以固定搭配高频出现,迅速回答「巴黎」。
问题是,世界上绝大多数知识都是出现频次低的「长尾事实」(Long-tail Facts),如数字力场公众号创立时间,就不是规律性知识。按图灵奖得主杨立昆的说法,大模型是高级复读机,「擅长模仿人类对话模式,却不懂背后的逻辑与含义。」碰到这类问题,它经常蒙圈。
由于训练目标是「最大化生成文本序列的联合概率」,不包含任何关于真实性的直接约束,对于不懂的问题,它倾向于编个像样的,而非坦承其短地说「我不知道」。
大模型幻觉问题连着的,是训练机制问题,更是数据质量问题——「真数据不够,脏数据来凑」之下,必然会出现上游水源(输入语料)污染导致下游水流(输出结果)浑浊的情况。
▲很多大模型都跳不出「垃圾进,垃圾出」的魔咒。
都知道,大模型的三大要素是算法、算力和数据,数据(语料)是源头活水。前两者可以靠优化,后者主要靠积累。
随着可用真实数据渐次枯竭,大模型如今普遍患上了高质量数据饥渴症。
不少大模型用合成数据解渴,想靠AI生成内容来推倒自己撞上的那堵「数据墙」。
但这很可能导致「模型崩溃(Model Collapse)」——2024年7月,《自然》杂志就对此发出预警,称随着模型继续在模型本身生成的越来越不准确的文本上进行训练,这类递归循环会导致模型退化,AI很可能「在短短几代内将原始内容迭代成无法挽回的胡言乱语。」
结果就是,AI「训」AI,越训越傻。
02 /
在幻觉问题上,「机器学习之父」迈克尔·欧文·乔丹曾表示,「单纯依靠暴力计算(Brute Force)无法解决智能的根本问题,反而可能因为数据噪声而产生系统性风险。」
诚如此言,大模型幻觉带来的破坏力不容小觑,一个程序bug也许会导致系统崩溃,但那是显性的,大模型幻觉则颇具隐蔽性,隐蔽性会强化其危害性。
首先,在医疗诊断、法律咨询、金融决策等边际容错率极低的领域,出现任何幻觉,都可能酿成严重后果,导致生命财产损失。
其次,AI胡编乱造容易导致错误信息谬种流传,带来社会空间信息污染,还消耗大众的技术信任度,拉低许多人的接受意愿。
还有,流沙上没法建大厦,幻觉问题若得不到有效控制,大模型的应用落地也会受影响。
大模型的进化形态,是成为能够主动执行复杂任务的智能体(Agent),但前置条件是可靠。毕竟,谁也无法安心委托那些可能会凭空捏造联系人信息、杜撰财报数据的AI助理,来处理重要事务。
▲大模型幻觉带来的危害不容小觑。
时至今日,幻觉已从技术瑕疵演变为AI产业化应用的现实掣肘。
当此之时,正如芯片产业已走出「兆赫兹竞赛」迷思那样,AI行业也该跳出「数据规模崇拜」和「参数军备竞赛热潮」。
从百亿到千亿再到万亿,过去几年,大模型领域的参数规模持续被刷新,仿佛数据量越大模型性能就越好。
这在初期确实成立,参数也并非不重要,但随着「更大的模型=更强的智能」等式在边际效用递减中失效,回归数据质量重要性高于数据集规模的理性判断,正当其时。中国最大的数据智能服务商明略科技提出「Clean Data > Big Model」,就意在于此。
要知道,现在AI行业已进入产业化落地阶段,用户(特别是企业级用户)在意的不是参数数字,而是模型在实际任务中表现出的可用性、可靠性——他们需要的是「可信AI」。
而控制幻觉,就是「可信AI」价值凸显期的决定性竞争维度。数据可信度也已取代数据集规模,成为大模型的核心竞争力。
03 /
正因来得普遍又极具危害,大模型幻觉不是个可以打个补丁的小bug,而是需要从系统层面去革新重构的根本性问题。
知名AI科学家、斯坦福大学教授吴恩达提出的「以数据为中心的AI(Data-Centric AI)」理念,就来得颇具针对性。他认为,AI模型开发过程中,业界过分关注模型架构的优化,却忽视了系统性地工程化数据质量。「如果80%的机器学习工作是数据准备,那么确保数据质量应该是团队最重要的工作。」
「以数据为中心的AI」跟传统的AI模型搭建范式「以模型为中心的AI(Model-centric AI)」有别,后者主要工作是改进模型参数,前者主要目标则是改善数据质量——「AI教母」李飞飞、AI大神安德烈·卡帕斯此前做的,其实就与此相关。
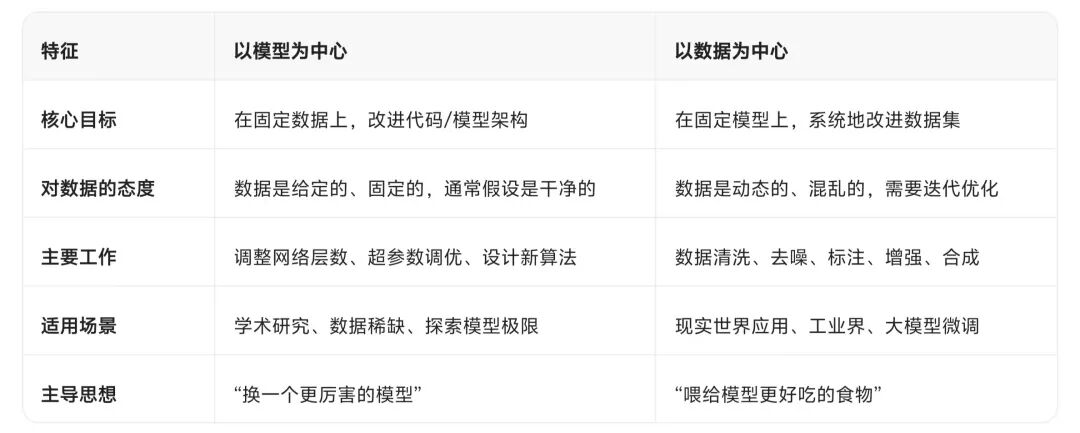
▲两种AI模型搭建范式的对照。
明略科技基于「Clean Data > Big Model」技术哲学系统性地发掘聚合跨领域的高可信信源,推出目前全球范围内最全面、最权威、最结构化数据源知识库——First Data,也与之呼应。
需要看到的是,对很多企业来说,获取干净、权威、实时的数据比训练一个模型要难得多。毕竟,大量高价值的权威数据「沉睡」在政府网站深处、PDF报告或复杂的交互式图表中,由于API接口众多、格式各异、标准不一,很难被机器自动解析。
First Data拟收录全球1000余个权威数据源(涵盖国际组织、各国政府、顶级学术机构),将分散、非标、难复用的原始内容,转化为可追溯、可验证、可引用的核心事实,不啻为大模型行业搭建了「可信数据源基础设施」,它不直接提供「数据」,但能解决「数据去哪找」问题。
《自然》杂志提到,提升模型准确性的重要途径是,访问原始数据源并在递归训练的模型中仔细过滤数据。
而First Data坚持100% URL验证标准,每个数据源都有完整文档,确保数据源真实可用。这直接回应了AI安全伦理范畴的「数据溯源(Data Provenance)」关切,能从源头阻断「幻觉引用」的可能性。
举个例子,用户问「2025年前三季度中国AI产业产值是多少?」通常情况下,AI会回忆训练数据再生成像样答案;有了数据索引导航工具First Data后,AI则可以指引用户前往权威信源处获取相关数据——在此过程中,First Data会充分顾及数据调用与数据跨境传输安全,推荐合规可靠的权威网站,并提供文件获取的逐步导航索引。
First Data的亮点不只是强调「数据溯源」,还有「权重分级」——那些数据源包含了访问链接并标注了API接口信息、更新频率、覆盖范围,更引入了 「六大权威等级分类」的创新做法。
这无疑是有的放矢:信源跟信源之间也有可信度差异。按权威程度分级,可以凸显高可信信源的优先序。
就拿查询「发展中国家经济数据」 来讲,First Data会优先推荐AI去世界银行官网而非商业资讯公司报告找数据,让AI尽可能避免低质量信息干扰。
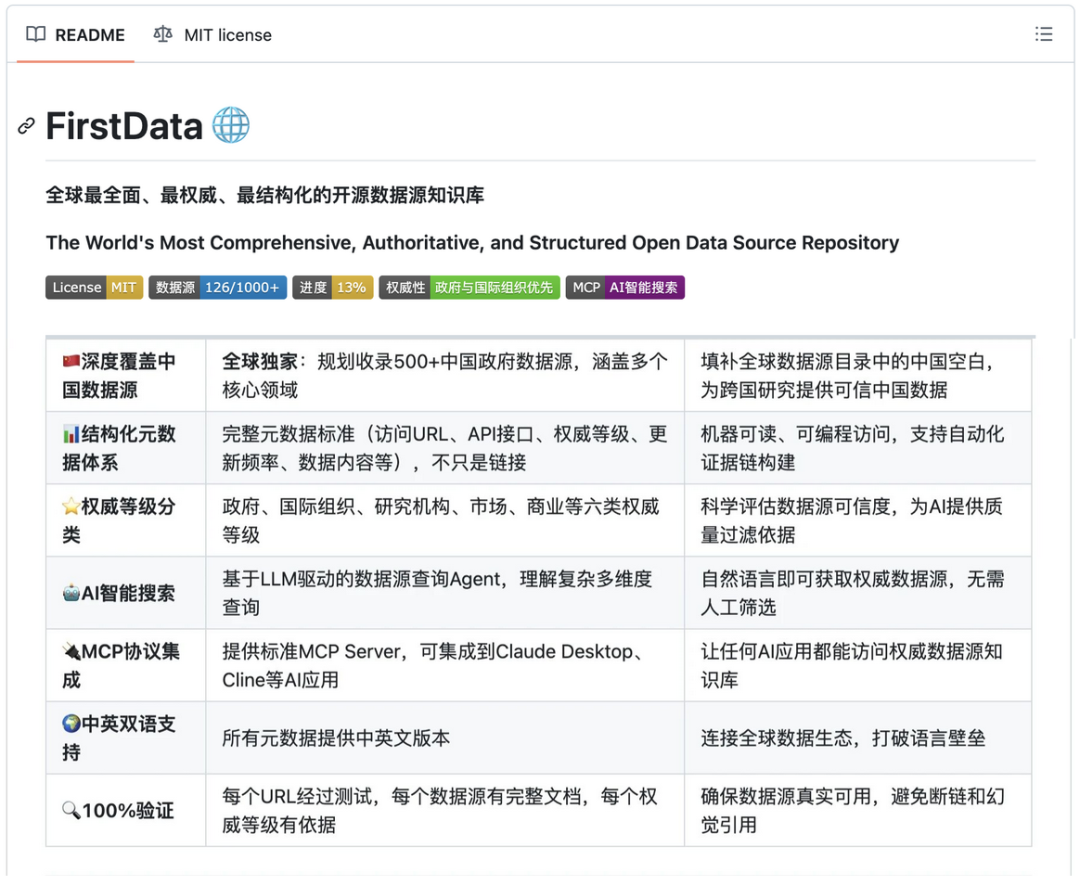
▲First Data建立了结构化元数据体系,还有权威等级分类。
舍此之外,开放开源也是First Data的醒目看点。1月28日,明略科技宣布正式开源First Data。这显然是盘大棋。
从商业竞争角度看,此举似乎有些「不值当」,但若是从深远层面看,以目前最宽松的开源协议MIT协议开源,是利他以自利。
一方面,这能丰富权威数据库。为了确保数据可信,Google Knowledge Graph此前通过语义搜索和NLP技术持续改进信息准确性,First Data则能走得更远——依托开源社区协作跟透明溯源机制,它可以建立「分布式数据源账本」。当全球数据科学家都能参与审核、补充数据源时,其可信度会远高于单一企业维护的数据库。
另一方面,这能带来技术普惠。First Data开源就像针对模型幻觉流行病的数字疫苗接种计划,让AI行业切实受益。
04 /
毫无疑问,在用户「苦AI胡编乱造久矣」的今天,AI行业需要可信数据底座。
而First Data建立的结构化元数据体系,就以可靠数据为锚,为整个行业提供了对抗「模型崩溃」的参照系,也为企业级RAG应用带来了权威数据层的即插即用解决方案。
对很多企业而言,它们无需自己去搭建数据基础设施,可以直接利用First Data构建的权威数据源网络,搭建可信的AI应用原型。
可以预见,有高质量数据加持,很多AI产品也能在降低幻觉中提升「办实事」能力,实现从ChatBot向智能代理的转变,伴随而至的,还有用户信任的提升:当AI推荐医疗方案引用的是权威医学数据库,预测经济走势依据是官方结构化数据时,大家自然更愿意采信。
着眼长远看,First Data开源的价值,还能朝填补全球数据源目录拼图中的「中国缺角」、为全球AI基础设施打造贡献「中国力量」两个层面延伸。
长期以来,国外大模型由于缺乏一手、权威、结构化的数据源,在被问到中国经济相关问题时,输出的答案经常并不标准,使得很多人只能雾里看花、产生认知偏差。
First Data项目代码库虽然本身不存储、不包含、不直接提供任何原始数据文件,但收录了公开权威数据源,还采用了中英双语元数据设计,可提供相关数据的推荐查询路径。
这么一来,用户通过大模型的指引,在权威信源处按图索骥获得可信数据后,势必能够提升全球使用者及AI模型对中国经济社会发展的理解深度,让更多人能直接准确地了解到中国经济的真实脉动。
跟西方科技巨头倾向于构建封闭的数据护城河不同,中国企业将全球最全权威数据源知识库开源,就如同对「中国开源VS美国闭源」模型发展路径里「中国路线」的致敬,也体现出了鲜明的价值取向:AI时代,数据可以是公共的资源,而非垄断的筹码。
从Linux到TCP/IP,历史表明,真正的数字基础设施都是开源的,只有开源,才能形成生态,只有形成生态,才能定义标准。中国企业以开源方式为全球AI行业完善贡献「中国维度」的数据标准,也是在把握主动权。
而这些价值的要义,就在于「真实」二字。
在今天,信息严重过载,事实极度稀缺,已构成了我们所处的信息环境。我们比任何时候都更需要可靠数据锚点,确保AI不是胡编乱造,而是言必有据。
First Data给出的解法便是:若AI爱胡编乱造,那就为数据「降噪」。到头来,其开源的深层价值,与其说是提供了大量权威数据源的工具箱,不如说是申明了某种技术伦理——
AI的核心价值点,不在能说得多像,在能说得多准;不在能生成多少内容,而在能创造多少可信价值。故而,数据可信度优于数据规模,信息可靠性重过生成流畅性。
真善美,真是善的前提。AI向善,先要向真。
✎作者 | 佘宗明
✎运营 | 李玩
欢迎分享到朋友圈转载须经许可