

作者|毛心如
2026 年的具身智能行业,正处在高速增长与理性回调的交汇点。
一方面,整机硬件的降本大潮如期而至,供应链的成熟度让硬件创业的门槛降到了前所未有的低点,灵巧手、传感器、执行器的成本与供应稳定性也比几年前好了不止一个数量级。
但另一方面,资本与市场的狂热正在遭遇冰冷的 PoC(概念验证)墙。
Demo 在实验室里丝滑流畅,但来到真实的工厂、物流仓库就变得时灵时不灵。
业内人总会问,为什么 LLM 已经迎来了 Scaling Law,而具身智能的泛化能力却迟迟没有迎来爆发?
喧嚣背后,回答其实渐渐浮出水面:
硬件已不再是强壁垒,模型算法也开始出现同质化,真正卡住产业化落地、限制机器人泛化能力的核心瓶颈,是高质量、可复用、贴近真实物理世界的交互数据。
数据荒带来的一个直接后果,是商业化落地的时间表被严重高估了。
前不久,我们跟灵初智能创始人兼 CEO 王启斌进行了一场深度对话,他说得很直白,行业里对商业化时间线存在集体忽视的乐观偏差。

大家普遍说今明两年是商业化爆发元年,但真实的工厂和仓库客户决策周期极长,一个项目从 PoC 到大规模采购可能需要 2-3 年,过度承诺商业节奏只会让行业信誉受损。
具身智能没有神话,未来两年的胜负手,唯一取决于数据周期。
半年前,当行业主流还在卷整机、热衷于做各种炫酷 Demo 吸引眼球时,灵初智能却做出了一次重大掉头。
在一年内估值暴涨六七倍的聚光灯下,这家公司坚守着小全栈路线,手握整机自研与设计能力,以及近乎信仰般 All in 人类原生数据的决心。
透过灵初智能的选择,我们能读懂当下具身智能最核心的命题,行业内卷早已从硬件比拼,切换到数据周期的深层博弈。

具身智能商业化被误区拖慢了
如今,具身智能硬件成熟度、模型算法能力已经能够撑起一些初步的场景落地。但行业规模就是起不来,且走得特别慢。
问题核心不在于技术本身,而是大家在数据逻辑和路线选择上,钻了不少死胡同。
最普遍的误区莫过于唯数据时长论。
行业扎堆追逐十万小时、百万小时的量化数字目标,误以为数据堆得越多,模型自然越强。
但数据价值从来不是按时长简单换算,任务多样性>物体多样性>场景多样性才是底层逻辑。
盲目重复同类场景、同类任务,只会堆砌大量无效冗余数据,根本无法带来泛化能力质变。
其次,神化遥操作的行业惯性根深蒂固。
早期受制于采集成本与技术条件,遥操作是权衡之下的最优解,但它与生俱来的结构性短板被忽视了。
隔着屏幕的远程操控,无论操作精度、临场判断还是动作自然度,都远不如人类现场原生作业状态。
生理感知和操作滞后,从一开始就锁死了遥操作的数据上限。
灵初智能内部做过对照试验,同等时长下,人类原生数据在精细操作、长程任务理解上,全面优于遥操数据。

还有一个被忽视的短板,是轻视全模态数据价值。
不少团队仅依赖 RGB 单视频训练,忽略 3D 关节角、触觉、语言标注等核心维度。
真正能适配长程灵巧操作的优质数据,必须是视觉、语言、关节、触觉四维一体。
单视频与全模态数据的能力差距,也是实验室效果完美、真机落地拉胯的核心原因。
与此同时,行业对仿真的态度也走向两极。
有人迷信仿真能补齐所有数据短板,也有人彻底否定仿真价值。

但仿真到现实的物理鸿沟是结构性难题,无法通过调参和优化物理引擎彻底消除。
但仿真并不是毫无意义,它更适合作为补充角色,用于长尾任务前期探索、世界模型强化学习样本生成,以及高风险极端场景的安全边界测试。
只是仿真数据仍然无法成为灵巧操作预训练的核心底座。
正是看到了这些行业共性,灵初智能选择跳出主流路线,不跟风遥操作堆量、不依赖仿真兜底、不盲目堆砌数据时长。

走出死胡同,All in 人类原生数据
2026 年被业内普遍视作具身智能数据元年。
行业竞争逻辑从比拼硬件参数、样机 Demo,全面转向数据话语权与标准定义权的深层博弈。
各家不再只埋头做模型、发整机,而是纷纷下场布局采集体系、数据集与评测规范,一场围绕数据定义权的争夺战已然拉开大幕。
放眼当下,行业已经分化出五种主流数据采集思路:遥操作、仿真合成、人类操作视频、UMI 和 Human-centric。

其中,人类操作视频、UMI、Human-centric 三条路径在今年集中爆发、快速出圈,成为行业探索新焦点。
人类操作视频依托第一视角拍摄,采集门槛低、素材体量庞大,能快速积累海量场景画面。
但短板同样突出,仅停留在 2D 视觉层面,缺失 3D 关节、力控、触觉等核心物理维度,只能学习表层动作表象,无法拆解精细交互逻辑,很难支撑精密装配等高阶灵巧任务训练。
UMI 主打低成本轻量化,通过手持夹爪 + 位姿感知的方式,把人类手势转化为机器人可学习轨迹,解决了传统遥操作成本高、绑定本体的痛点,实现了数据采集的降本平权。
但它的局限性也很明显,硬件自由度有限,精细手部维度缺失,模态不够完整,更适合简单重复性任务,难以适配长程、高精度的复杂作业场景。
可以看到,无论是老牌的遥操、仿真,还是今年爆火的视频、UMI,都能解决有没有数据的问题,却始终跳不出各自的能力边界。
要么成本与规模无法兼顾,要么模态残缺、精度不足,要么跨不过仿真现实鸿沟,只能作为阶段性过渡或补充方案,很难成为通用具身智能的核心数据底座。
五类路径里,Human-centric,以人为原生全模态采集被普遍认为最具备长期成长价值。
它跳出间接采集、局部还原的思路,直接从人类真实作业行为出发,完整复刻任务逻辑、手眼触觉闭环与临场自适应能力。
这种从根源贴近物理世界运行规律的方式,是目前最有可能打破现有路线天花板的高阶范式。
而灵初智能,选择的就是 All in Human-centric 人类原生数据。
依托自研外骨骼手套,其已实现亚毫米级精度的全模态数据采集。
基于自身对于数据价值的观察,灵初智能在传统数据分层思维上,重新梳理出真机数据价值小金字塔。
把真机数据清晰划分成人类原生数据、传统遥操数据、机器人作业回流数据三个层级。
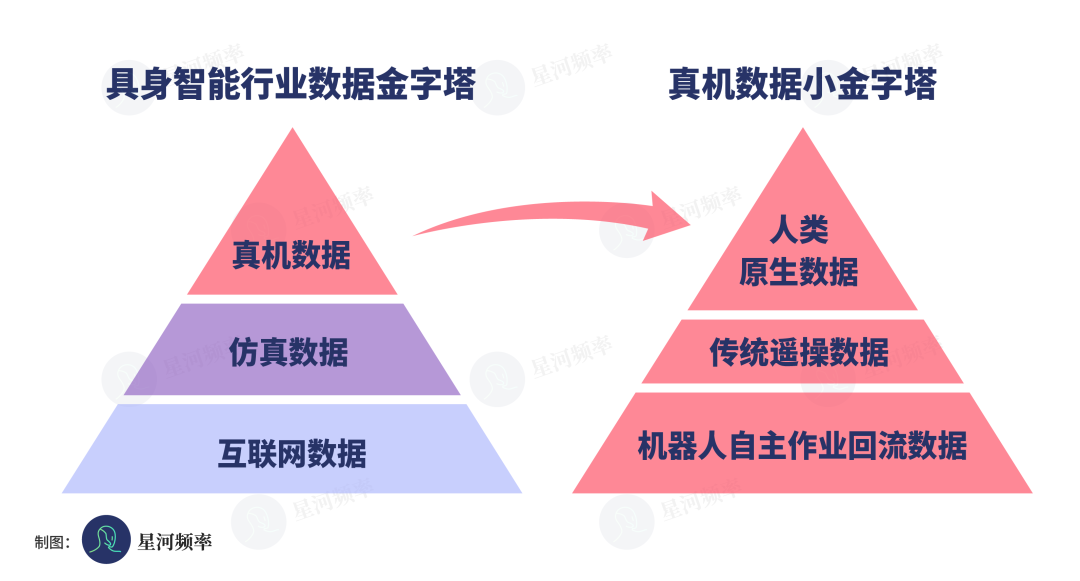
在这套框架下,他们果断聚焦金字塔最顶端的高价值原生数据,主动绕开天花板有限的遥操作中间路线,把资源全部集中在最具备长期潜力的数据底座上。
不走过多弯路,也不浪费算力与采集成本在低效数据上。
在这个基础上,灵初智能还建立了一套自有的高质量数据评判体系。
明确 3D 关节角、触觉、视觉的模态权重优先级,坚守亚毫米精度准入标准,坚持全模态不可缺失。

此外,更打破了行业只留存成功样本的惯性,主动纳入 30% 失败案例用于模型边界学习,用更完整的数据视角,让机器人真正读懂真实物理世界的容错逻辑。
当行业还在五条路线里左右取舍、纠结成本与精度的平衡时,灵初已经锚定 Human-centric 长期路线。
一边搭建采集硬件与数据管线,一边定义数据质量、分层逻辑与训练规范,在数据元年的定义权争夺战中,走出了一条理念与工程并行的差异化路径。

百万小时数据飞轮,怎么真正转起来?
选对数据路线、建立评判标准只是起点,真正的壁垒,在于能不能搭建一套可规模化、可自迭代、可商业变现的数据飞轮。
为了解决大规模采集成本难题,灵初智能选择自研外骨骼数采手套,把单位采集成本降到传统真机方案的十分之一。
同时稳定保持亚毫米级轨迹精度,扫清海量数据采集的经济障碍。
在此基础上,他们搭建了四条并行的规模化采集渠道:
深入制造、物流产业客户现场驻场采集,在业务落地的同时同步沉淀高价值数据。
与专业数采基地合作,搭建标准化、常态化的固定采集场地。
与专业具身数据平台深度合作,借力成熟的数据服务能力拓宽来源。
布局分布式微支付采集网络,面向普通用户开放手套租赁与购买,用户在家完成标准化简易操作即可按时获取报酬,低成本覆盖工业场景难以触及的长尾日常动作场景。
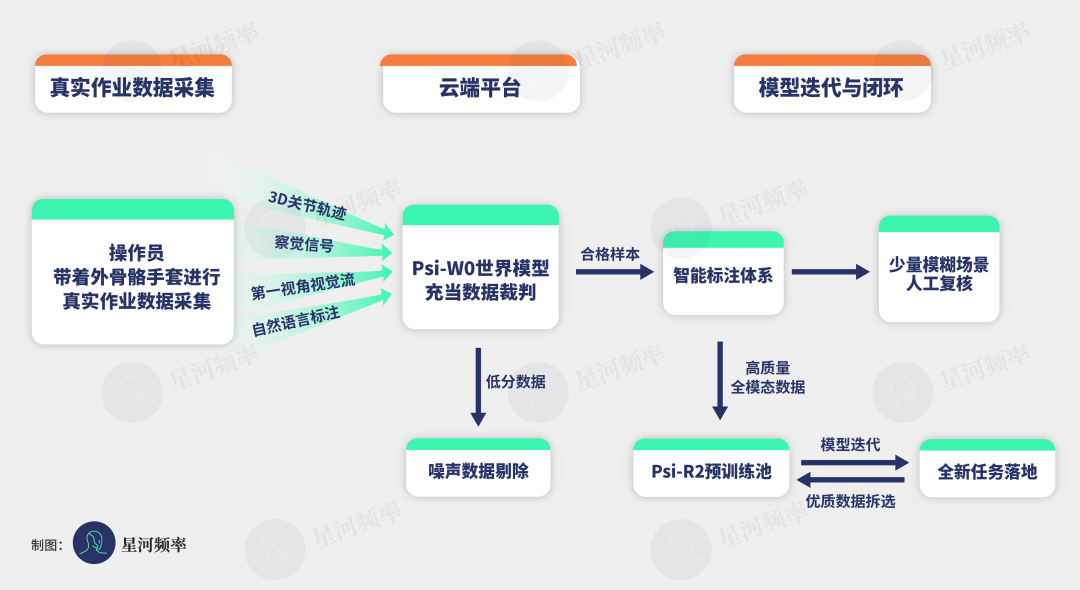
针对分布式采集人员动作参差、画面易遮挡等问题,灵初通过标准化运营 SOP+Psi-W0 世界模型智能质检双重兜底,自动打分过滤低分噪声,从源头守住数据纯度。
这套数据流水线已经完全跑通:
操作员在真实场景完成全模态采集后,数据进入云端自动质检,再经智能标注(内含少量人工复核)汇入 Psi-R2 预训练池。
面对新任务,只需少量真机轨迹微调;同时,世界模型通过强化学习生成合成样本,优质数据又会回流,推动持续迭代。
这套数据飞轮已经在实际落地中得到明确验证。
半年前新任务需要数百条真机演示才能稳定落地,如今不足百条样本,就能完成手机装配、工业包装、叠纸盒等高复杂度长程操作。
这意味着,模型能力不再是简单数据线性堆砌,而是进入指数级泛化提升阶段。

类比 LLM 量级跃迁带来的能力涌现,具身智能同样存在百万小时临界点。
灵初智能计划 2026 年第三到第四季度冲击 100 万小时人类原生数据量级,搭建覆盖多场景、多任务、多物体的灵巧手全模态数据集。
除此之外,灵初智能还跑通了三重数据变现路径,分别是外骨骼硬件租售、数据集授权、模型 + 灵巧手 + 数据一体化产业方案,让数据从纯研发投入,变成可复利、可沉淀、可形成壁垒的核心资产。

不跟风统一大模型,双模型各司其职
数据飞轮转起来了,用人类原生数据喂出来的模型,到底行不行?
灵初智能的答案是两个模型、一套理念。
Psi-R2 策略模型专注学习任务怎么完成,只投喂高质量的成功操作轨迹,负责长程任务规划与动作策略生成。
Psi-W0 世界模型负责理解物理规律,用失败样本和边缘案例做虚拟试错,判断动作合理性。
两套模型的训练目标完全拆分,互不干扰,这一点是灵初智能跟行业流行的统一大模型包揽一切路线最不一样的地方。
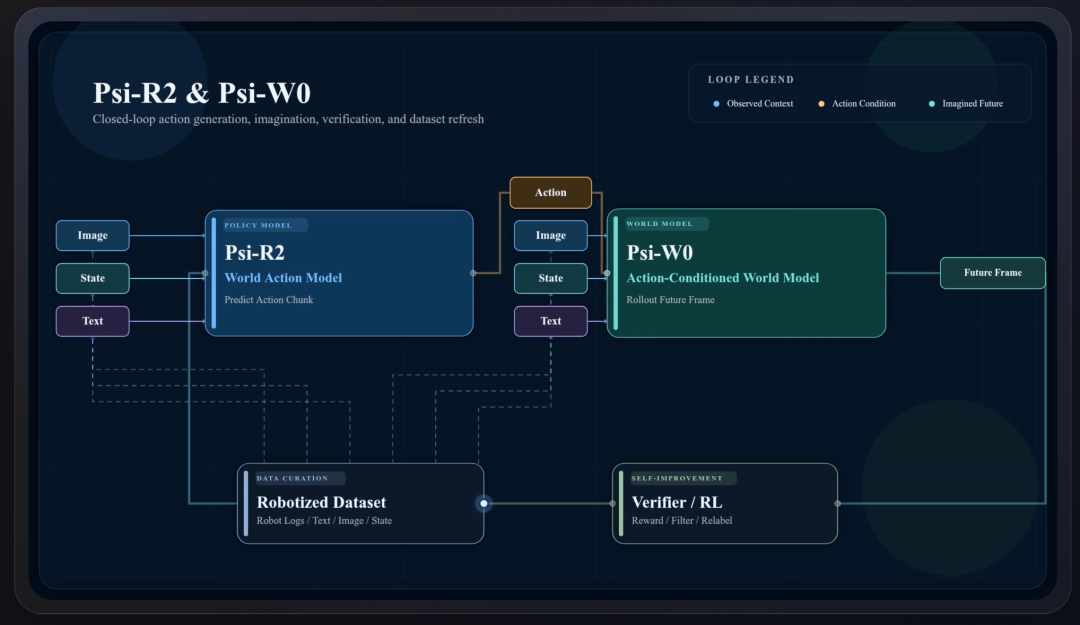
有人会问,为什么不合并成一个超大模型?
核心在于两套模型的训练目标存在本质矛盾:一个专注学习成功路径,一个专注理解物理规则,强行融合只会互相牵制。
在技术理念上,灵初智能坚持原始数据进,原始数据出的极简思路,尽可能减少人工规则干预。
王启斌坦言,数据体量不足的时候,这种朴素架构效果确实不如精心调校的模块化方案。
但当人类数据底座突破十万小时后,模型的泛化能力和少样本迁移能力开始全面反超。
另一个难点是,人手 21 个自由度向不同构型机械手迁移这类跨本体映射,是行业公认的技术难题。
灵初智能选择不靠人工规则穷举,只做最粗粒度的关节标定,剩下的精细映射全部交给 Psi-W0 通过强化学习自主摸索。
即便明知加一条人工规则就能快速修复问题,团队也选择尽可能不干预,避免局部优化影响全局泛化能力。
而这套模型能力也有经得起考验的硬指标。
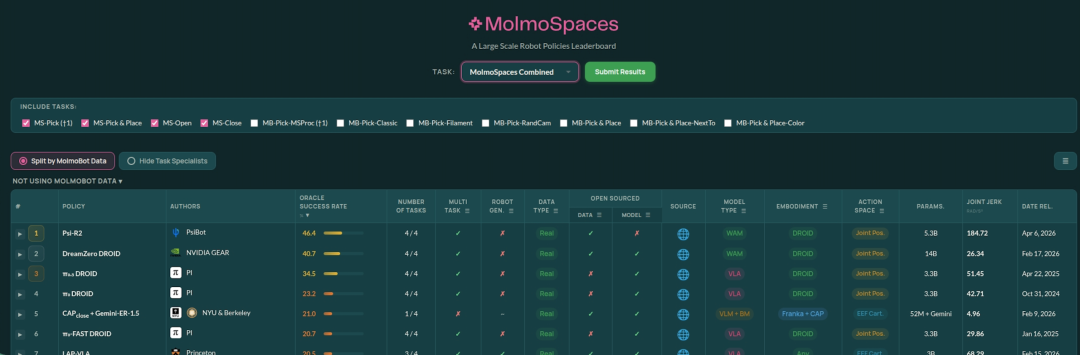
在 MolmoSpaces 多模态评测中,灵初智能的模型拿下了全球第一的成绩。
在 MolmoSpaces Combined 榜单,且不使用 MolmoBot Data 的分组中,Psi-R2 以 46.4 的 Oracle Success Rate 排名第一,并覆盖 4 个任务。
此外,Psi-R2 在评测中超越了 π0.5、DreamZero 等国际知名模型,表现明显优于其他基线模型。
这至少证明了一件事,用人类原生数据训练出来的模型,不只是在工厂里能干活的专用工具,在通用能力上也站得住。

不卷整机,不囤数据,不吹节奏
完整的数据采集、质控、模型迭代飞轮体系成型之后,灵初智能更进一步,选择逆赛道常态的战略取舍。
在大家普遍将数据视为核心底牌的当下,灵初智能选择主动开源首批 1000 小时高质量人类手部全模态操作数据。
跳出囤积数据的行业惯性,其以标准化开源数据锚定行业规范,破除数据孤岛、格式杂乱、评测无据的产业痛点。
在王启斌眼中,行业标准依托数据与技术落地,伴随全球产学研依托这套数据范式研发,全行业研发标准将逐步趋同,生态话语权远胜于存量数据壁垒。
灵初智能也明确了开源不会影响核心优势。
静态数据集不是壁垒,自研采集硬件、自动化数据管线、真机落地算法构成的闭环体系,才是难以复刻的护城河。

也正是这种对数据本质、行业规律的深度认知,让灵初智能在 2026 年具身智能资本热潮中,保持了极其克制的节奏。
王启斌主动做了三个取舍。
整机层面,他把重资产环节交给成熟供应链,自己的精力全部锁死在数据、模型、灵巧手这个闭环里。
这三者从设计理念来看,呈现高度耦合,数据采集直接服务于模型训练,模型输出又反哺灵巧手的控制算法。
节奏层面,他不盲从行业的商业化爆发元年叙事,把 PoC 到规模化的周期拉到 2-3 年,给数据沉淀留出真实时间。
场景层面,他主动避开家庭等高风险地带,先在精密装配和服装仓储两个确定性场景里扎深打透。

总的来看,灵初智能的开源布局、边界坚守与节奏克制,本质都是一套去泡沫、去浮躁、去捷径的长期主义打法。
放弃短期行业热度与资本红利,换来了数据体系的稳定迭代、飞轮机制的自驱生长与落地能力的持续跃迁,为后续完整的数据飞轮高速运转、百万小时数据底座打下了坚固的根基。
回过头来看灵初智能的一系列选择,它其实在回答一个更根本的问题。
当硬件不再是护城河,当模型架构逐渐趋同,一家具身智能公司到底还能靠什么活下来、并活得久?
王启斌的答案是,数据定义的权利,以及让数据飞轮自转起来的体系能力。
这种定义权与体系能力,最终都沉淀在灵初智能自己的模型上。依托自研双模型架构,可落地、可泛化的核心产品实力有了绝对的保障。
这不是一个靠融资烧出来的故事,而是一个得靠笨功夫垒出来的壁垒。
外骨骼手套的迭代、数据管线的打磨、极简的技术架构,每一件都不是性感的事,但都在向技术临界点靠近。
尽管行业还在等那个临界点的到来,但至少,灵初智能已经用 10 万小时的数据、MolmoSpaces 全球第一的模型成绩、以及不到 100 条演示就能完成新任务的冷启动效率,证明了这条路值得走下去。
具身智能的终局还很远。
在通往终局的路上,比的不是谁的口号更响亮,而是谁的数据更干净、谁的飞轮转得更快、谁更能忍受寂寞去采集一条条人类操作。
百万小时人类原生数据的目标也不是终点,而更像是一张通往具身智能下一阶段的门票。