

过去两年,AI产业的叙事中心一直围绕大模型展开:参数规模、训练效率、推理成本、模型能力边界。
可当OpenClaw代表的Agent落地到千行百业,越来越多的问题浮出水面:一个能够理解任务、调用工具、访问数据、编排流程、持续执行的智能体,需要的不仅是基础算力和模型,而是一套完整的运行体系。
问题在于,什么是适合Agent的运行体系呢?
5月22日的KADC2026鲲鹏开发者峰会上,天翼云联合鲲鹏给出了清晰的答案——构建Runtime、Token与Data协同的AI全栈云底座。
01 底座重构,企业AI正在从“调API”走向Agent Native
很多企业做AI应用,本质上是在“调接口”:前端套一个聊天框,后端接一个大模型API,再接几个业务插件。
这样的模式,曾是两年前的主流思路,但在Agent时代已经行不通。
因为企业业务不是单轮问答,常常是跨系统、跨角色、跨流程、跨权限的连续任务,一个真正可用的Agent,既要能理解任务,也要能调用ERP、OA、CRM、知识库、浏览器、代码环境等工具。折射到企业的IT架构上,AI不能停留在“外挂能力”的阶段,必须变成云原生架构中的一层运行时。

天翼云公有云事业部研发专家周望在演讲中提到,天翼公有云当前的AI全栈产品体系被划分为三个模块。
第一个是Agent Infra,提供Agent Runtime、Agent沙箱、流程模式、中间件、Serverless底座等核心运行能力。可以理解为智能体运行的“水电煤”,解决了任务怎么拆解、工具怎么调用、状态怎么保存、异常怎么回滚、权限怎么隔离、多个Agent之间怎么协同等应用和运行问题。
第二个是AI Infra,包含异构算力池化调度、推理加速、密态计算、智算网络等算力与引擎能力。简单来说,就是为Agent提供稳定、高效、低成本的“动力系统”,解决的是怎么让每一个Token生成得更快、更便宜、更安全,怎么让每一个Agent任务跑得更稳、更流畅、更可持续。
第三个是Data Infra,涵盖向量存储、极速缓存、可信数据空间等数据服务。Agent执行任务的过程中,需要持续调用企业内部的知识库、业务数据、历史记录和外部信息,Data Infra的价值正是让Agent在执行任务时能够快速检索、精准调用、稳定读写,并且保证数据安全和权限可控。
三个模块实现了上层应用到底层算力的全覆盖,同时也揭示了Agent时代的生存法则:影响智能体能否落地的因素,不只是模型本身,关系到运行、数据、安全与成本控制在内的全套能力。
企业需要的不是一个个孤立的Agent应用,而是一个能够承载智能体开发、部署、运行、治理和运营的统一底座,企业的AI基础设施正在从“Model Native”走向“Agent Native”。
在Model Native的架构下,主要提供算力、模型训练、推理接口、API调用,目标是让企业“用上大模型”;而Agent Native架构的要求,进一步升维到智能体运行所需的能力,需要原生融入云基础设施中,涉及任务编排、工具调用、上下文管理、长期记忆、权限隔离、数据访问……不再是应用层临时拼接出来的功能,而是AI基础设施的标准能力。
就像天翼云所示范的:Agent Infra解决运行框架,AI Infra解决推理效率,Data Infra解决数据支撑,三者合在一起,才让Agent从一个“会对话的应用”,变成了适合千行百业的生产力引擎。
02 跨越瓶颈,软硬协同攻克“失忆症”与“成本陷阱”
Agent进入企业的生产环境后,摆在案头的是一个更加棘手的问题:一份份近乎“天价”的算力账单。
和AI进行对话时,每次只需要完成一次回答,但企业Agent要处理长任务、多轮交互、多工具调用、多步骤规划。一旦任务链条变长,问题就会集中爆发,其中被诟病最多的瓶颈有两个:
一个是“失忆症”,由于初期任务信息易丢失、缺少全局最优规划、缺乏自我修正机制等,导致长序列任务准确度较低。
另一个是“成本陷阱”,因为历史上下文不可压缩、失败重试与冗余路径增加等原因,Token消耗随对话轮次指数级膨胀。
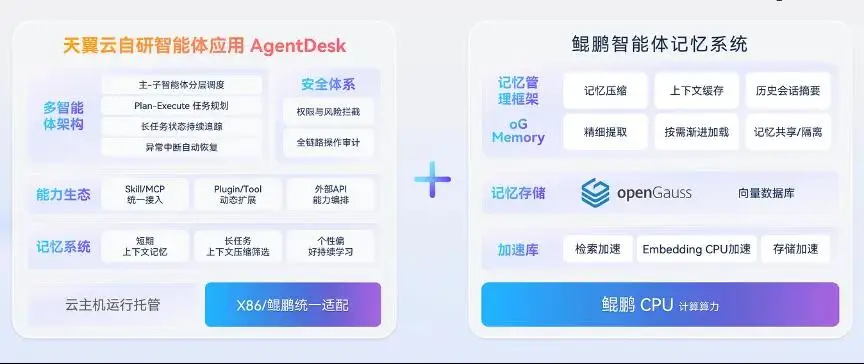
面对横亘在千行百业面前的难题,天翼云和鲲鹏的合作没有止步于算力:天翼云自研的智能体应用AgentDesk与鲲鹏智能体记忆系统进行了协同增强,用软硬协同方式消除了Agent长任务场景的系统瓶颈。
核心思路是引入鲲鹏oG-Memory管理框架,通过记忆压缩、上下文缓存、精细提取、按需渐进加载、历史会话摘要、记忆共享/隔离等能力,以及openGauss的向量存储,鲲鹏的检索加速、Embedding CPU加速、存储加速等能力,在保留关键记忆的同时,降低推理过程中的Token开销。

以LoCoMo长序列任务测试为例,AgentDesk+鲲鹏智能体记忆系统组合交出了一份实打实的高分答卷:在长序列任务中的准确度达到90.8%,较原生OpenClaw提升了37%,较AgentDesk提升了36%;输入Token消耗仅236万,比原生OpenClaw降低了68%,比AgentDesk降低了30%。
隐藏在数字背后的,是软硬协同的融合创新范式。
不少Agent框架处理长期任务,采用的是“堆上下文”的方式。结果就是,任务越长,塞进去的历史越多,Token成本越高,模型注意力越分散。看似记忆比较完整,实际效率随着对话轮次越来越低。
天翼云和鲲鹏的实践,没有简单地把历史对话塞回上下文,而是把记忆从上下文窗口里“拆出来”,变成一套可检索、可压缩、可分层、可隔离、可加速的数据基础设施。在Agent执行任务的过程中,模型不需要每次吞下全部历史对话,可以在需要时按需加载关键记忆。
把视角再放大一些,天翼云和鲲鹏明确了一个方向:Agent的能力边界,不只由模型决定,Runtime、Memory与算力基础设施的协同,将是AI从对话机器人走向数字员工的分水岭。
不只是长期记忆系统,在Agent的安全治理方面,天翼云和鲲鹏有着相同的原则——“让AI在边界内行动”。
天翼云的智能体引擎AGE打造了浏览器、代码、手机等沙箱系统,鲲鹏超节点的沙箱系统进一步实现了快速启动、高密部署和快速回滚,正在以双向奔赴的形式让Agent既能高效、准确、低成本执行任务,且始终被限制在可隔离、可回滚、可审计的安全边界内。
03 写在最后
智能体时代的AI基础设施,将从“应用中心”转向“Agent中心”,从“模型接入”转向“运行体系”,从“单点智能”转向“全栈协同”。
大模型并没有消失,而是退到了幕后,成为AI计算底座中的一项基础能力。左右决定企业AI落地速度的,是能否把模型、算力、数据、工具、记忆、安全和成本统一起来。谁先拥抱Runtime、Token与Data协同的AI全栈云底座,谁就更有机会拿到Agentic AI时代的“船票”。